本帖最后由 loria 于 2025-1-17 15:09 编辑
一:项目简介
本文分享的是基于YOLO训练出来的水果目标检测模型部署在行空板上运行的项目,旨在实现从实时视频流中框出画面中的所有水果并显示其名称。

二:项目效果
话不多说,先放上效果视频
[media=x,500,500] https://b23.tv/mtCbZ6s[/media]
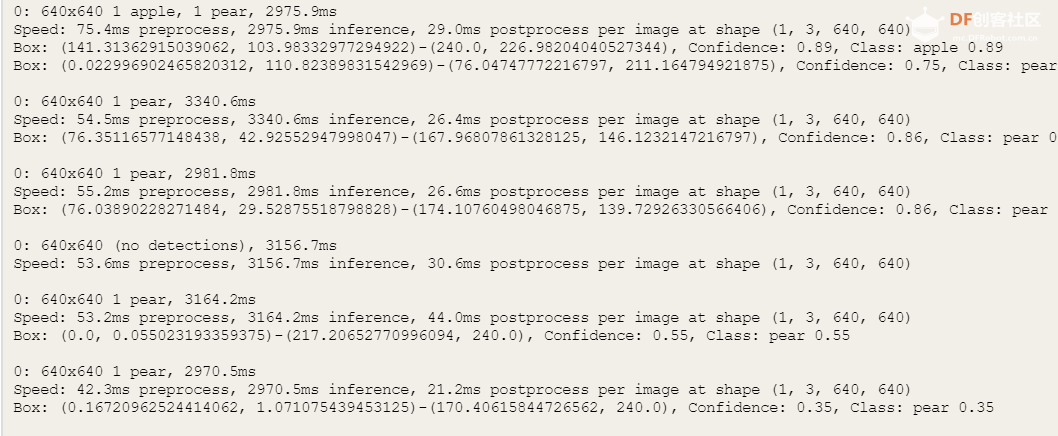
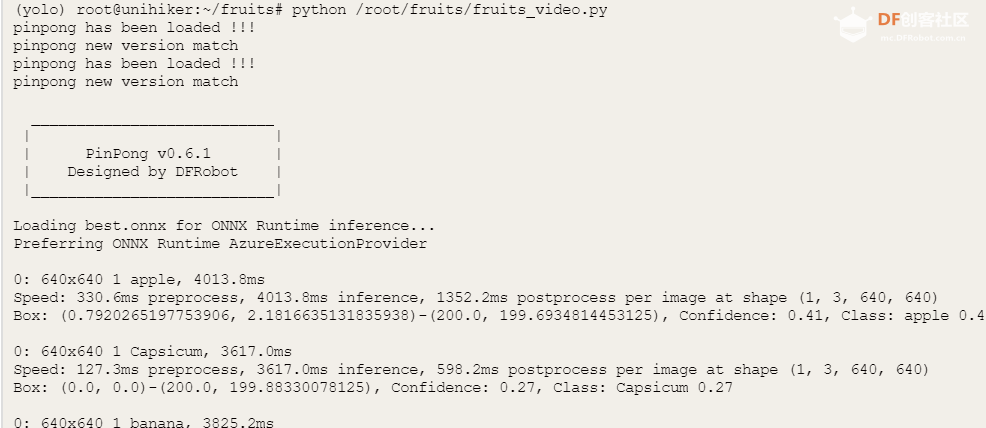
根据终端的显示针对图像尺寸为640*640 的图片,每次推理大约耗费2-3秒,对于行空板的性能来说,是比较好的效果。
三:软硬件
接下来,我将分享项目的制作过程。
使用到的软件是Mind+
使用到的硬件有:
(1)行空板M10
行空板M10是一款专为Python学习和使用设计的新一代国产开源硬件,采用单板计算机架构,集成LCD彩屏、WiFi蓝牙、多种常用传感器和丰富的拓展接口。同时,其自带Linux操作系统和Python环境,还预装了常用的Python库,让广大师生只需两步就能进行Python教学。

(2)USB摄像头

四:项目准备
行空板部署YOLO系列项目需要python3.1.0以上的环境,为了更好的管理不同版本的python环境,推荐使用MiniConda
请参考此篇帖子的环境配置教程:如何在行空板上运行 YOLOv10n?
请按照这篇帖子的教程完成到Step 7 安装utralytics
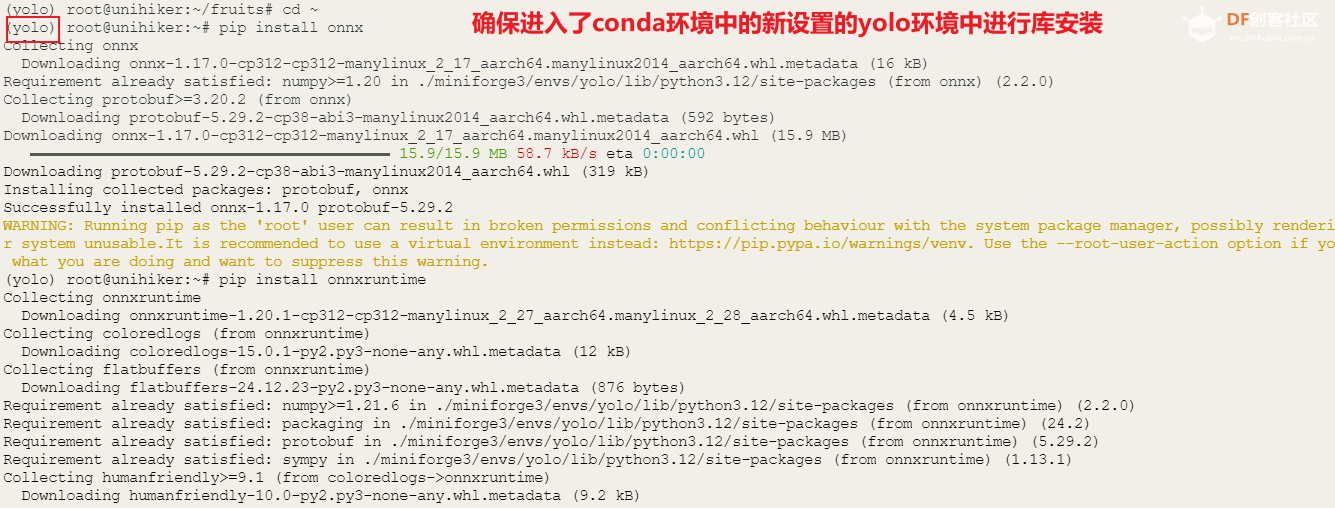
除了utralytics库本项目还需要使用onnx、onnxruntime、opencv -python 和pinpong库
请依次在终端输入以下命令(注意行空板需要联网)
- pip install onnx
- pip install onnxruntime
- pip install opencv-python
- pip install pinpong
 五:项目实现 五:项目实现
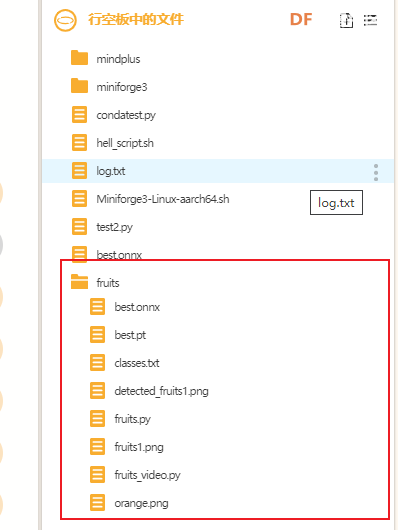
做好准备后,可以编写代码实现项目了。我将模型文件和运行代码都放入了一个名叫fruit的文件夹中,将文件夹拖入Mind+右侧项目中的文件中,右键选中上传到行空板

可以在行空板中的文件找到上传的fruit文件,其中“best.pt”是YOLO水果检测模型文件,“best.onnx”是onnx格式的模型
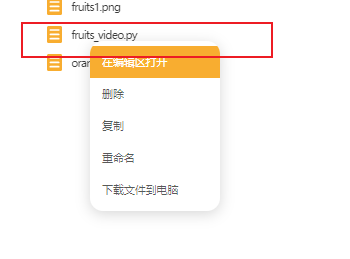
选中名为“fruites_video.py”的文件,选择在编辑区打开
fruits_video.py是模型推理py文件,详细的内容如下。简单来说实现的功能是读取摄像头的每一帧画面裁剪成240*240的尺寸,作为输入进行推理,根据推理结果框出画面中的水果并显示其类别名称- # -*- coding: UTF-8 -*-
-
- # MindPlus
- # Python
-
- # 导入必要的库
- import cv2 # 用于图像处理和视频捕获
- from pinpong.board import Board, Pin # 用于与MindPlus硬件板进行交互
- from ultralytics import YOLO # 用于加载和运行YOLO模型
- from pinpong.extension.unihiker import * # 导入UniHiker扩展模块
-
- # 初始化MindPlus硬件板
- Board().begin()
-
- # 加载导出的ONNX模型,用于目标检测任务
- onnx_model = YOLO("best.onnx", task='detect')
-
- # 使用OpenCV打开默认摄像头
- vd = cv2.VideoCapture(0)
- vd.set(cv2.CAP_PROP_BUFFERSIZE, 1) # 设置缓冲区大小,提高稳定性
-
- # 创建一个全屏窗口用于显示结果
- cv2.namedWindow('winname', cv2.WND_PROP_FULLSCREEN)
- cv2.setWindowProperty('winname', cv2.WND_PROP_FULLSCREEN, cv2.WINDOW_FULLSCREEN)
-
- # 循环捕获视频帧
- while True:
- if vd.isOpened(): # 检查摄像头是否成功打开
- ret, frame = vd.read() # 读取一帧图像
- if not ret: # 如果读取失败
- break # 退出循环
-
- # 获取原始图像的尺寸
- h, w, c = frame.shape
-
- # 计算中心裁剪的起始和结束坐标
- # 这里假设图像是正方形的,如果不是,需要调整代码
- start_x = (w - h) // 2
- start_y = (h - h) // 2
- end_x = start_x + h
- end_y = start_y + h
-
- # 从原始图像中裁剪出中心区域
- crop_frame = frame[start_y:end_y, start_x:end_x]
-
- # 将裁剪出的图像缩放到 200x200 的尺寸
- resized_frame = cv2.resize(crop_frame, (240, 240))
-
- # 使用裁剪和缩放后的图像进行推理
- results = onnx_model(resized_frame)
-
- # 绘制检测框和标签
- for det in results[0].boxes.data.tolist():
- x1, y1, x2, y2, conf, cls = det
- label = f"{onnx_model.names[int(cls)]} {conf:.2f}"
- cv2.rectangle(resized_frame, (int(x1), int(y1)), (int(x2), int(y2)), (255, 0, 0), 2)
- cv2.putText(resized_frame, label, (int(x1), int(y1) - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (255, 0, 0), 2)
-
- # 显示结果
- cv2.imshow("winname", resized_frame)
-
- # 打印检测框和标签信息
- for det in results[0].boxes.data.tolist():
- x1, y1, x2, y2, conf, cls = det
- label = f"{onnx_model.names[int(cls)]} {conf:.2f}"
- print(f"Box: ({x1}, {y1})-({x2}, {y2}), Confidence: {conf:.2f}, Class: {label}")
-
- key = cv2.waitKey(1) # 等待1毫秒,检测按键事件
- if key == 27: # 如果按下ESC键
- break # 退出循环
-
- # 释放资源
- vd.release()
- cv2.destroyAllWindows() # 关闭所有OpenCV创建的窗口
复制代码
打开fruits_video.py文件后点击运行即可
运行成功后,终端显示如下
六:项目反思
根据实践结果,行空板部署实时目标检测项目,训练模型时输入尺寸在128*128及以内FPS有较好的数据效果。本项目可以进一步在模型上进行优化以降低画面延迟率
| 
 编辑选择奖
编辑选择奖



 沪公网安备31011502402448
沪公网安备31011502402448

 置顶卡
置顶卡 变色卡
变色卡 千斤顶
千斤顶






